The following notes describe how to migrate from a single sNow! server to multiple sNow! servers working in High Availability (HA) cluster and a shared file system provided by external servers.
This guide assumes that:
- You have at least two nodes to install sNow!
- The NFS client has been installed in sNow! nodes
- The /sNow path is mounted directly from NFS or it’s a mount bind to that path
- The /home path is mounted directly from NFS or it’s a mount bind to that path
- You have followed the instructions defined here
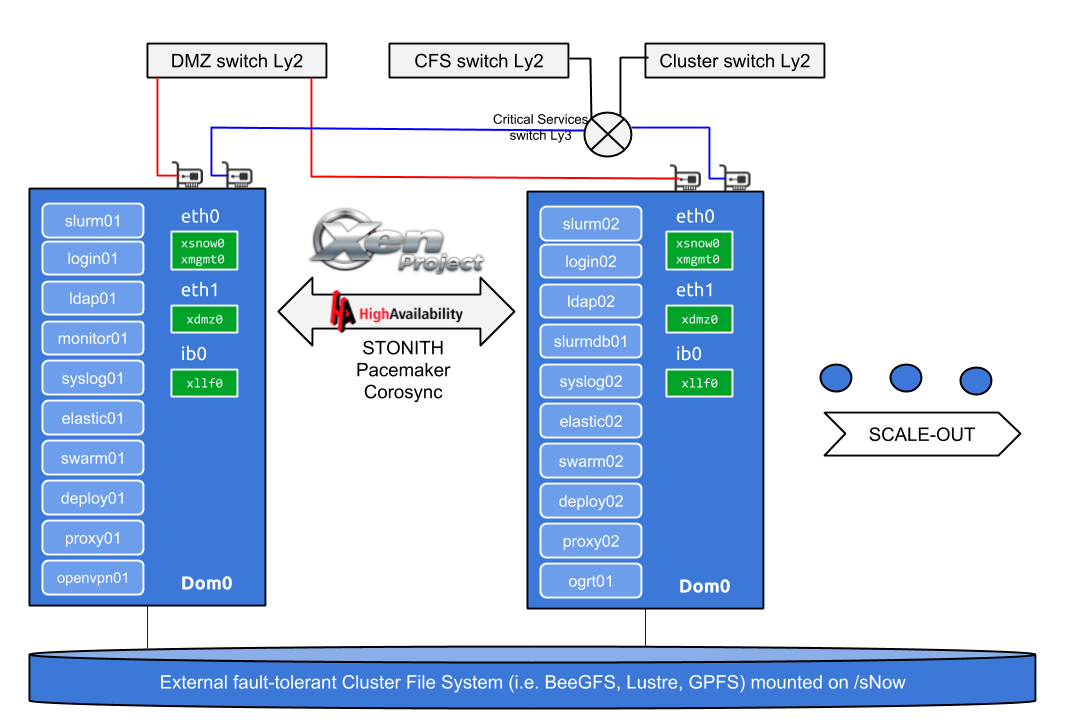
Domain Images Migration
By default, the domains OS images are stored in logical volumes managed by LVM2.
The parameter IMG_DST defines how the images are stored.
IMG_DST='lvm=snow_vg': the domains OS images are stored inside a Logical Volume created in the snow_vg Volume Group.IMG_DST='dir=/sNow/domains': the domains OS images are stored inside loopback files located inside /sNow/domains folder.IMG_DST='nfs=$NFS_SERVER:/sNow/domains': the domains OS images are stored and exposed through a NFS server.
If your IMG_DST is set to IMG_DST='lvm=snow_vg', you will need to migrate those images to a loopback image files or to create additional NFS exports to enable HA mode over a shared file system. The following steps will guide you to migrate domain OS images from LVM to loopback files.
- Stop the domains:
snow shutdown domains - Create a script with the following content. This will dump the file system to a loopback file for each domain and update the domain configuration files:
#!/bin/bash for domain in $(snow list domains| egrep -v "Domain|\-\-" | gawk '{print $1}'); do mkdir -p /sNow/domains/$domain dd if=/dev/snow_vg/${domain}-disk of=/sNow/domains/${domain}/${domain}-disk dd if=/dev/snow_vg/${domain}-swap of=/sNow/domains/${domain}/${domain}-swap sed -i "s|phy:/dev/snow_vg/|tap:aio:/sNow/domains/$domain/|g" /sNow/snow-tools/etc/domains/$domain.cfg done - Run the script:
./migrate_lvm2loopback - Try to boot the domain:
snow boot domain_nameInstall sNow! software in the new sNow! servers
At this point, the new sNow! servers should have the NFS client setup and the sNow! release should be the latest stable release.
Install sNow! software as usual with the install.sh file available in the /sNow/snow-tools:
cd /sNow/snow-tools
./install.sh
Once the installation is completed, you will need to reboot the server in order to boot with the new kernel.
Initiate sNow! with snow init once the new nodes are up and running. This command will print the following warning message.
root@snow02:~# snow init
[W] sNow! configuration had been initiated before.
[W] Please, do not run this command in a production environment
[W] Do you want to proceed? (y/N)
At this point, it’s safe to proceed because you are initiating new nodes. Please, don’t consider to run this command in a production environment.
Install the required software packages on all the sNow! servers
apt update
apt install libqb0 fence-agents pacemaker corosync pacemaker-cli-utils crmsh drbd-utils -y
Do the same in the other sNow! nodes
Disable auto start of corosync and pacemaker
In order to avoid a death match situation, it’s highly recommended to disable corosync and pacemaker to be started at boot time. To start the service, you only need to start pacemaker.
systemctl disable corosync
systemctl disable pacemaker
Do the same in the other sNow! nodes
Setting up Corosync
Generate keys
corosync-keygen
Corosync Cluster Engine Authentication key generator.
Gathering 1024 bits for key from /dev/random.
Press keys on your keyboard to generate entropy.
Setup the right permissions
chmod 400 /etc/corosync/authkey
Transfer the key to the other nodes
scp -p /etc/corosync/authkey snow02:/etc/corosync/authkey
Configuring corosync
The content of /etc/corosync/corosync.conf should be something similar to the following example. Note that this cluster only has two nodes (snow01 and snow02).
# egrep -v "^$|#" /etc/corosync/corosync.conf
totem {
version: 2
cluster_name: snow
token: 3000
token_retransmits_before_loss_const: 10
clear_node_high_bit: yes
interface {
ringnumber: 0
bindnetaddr: 192.168.8.0
mcastport: 5405
ttl: 1
}
}
logging {
fileline: off
to_stderr: no
to_logfile: no
to_syslog: yes
syslog_facility: daemon
debug: off
timestamp: on
logger_subsys {
subsys: QUORUM
debug: off
}
}
quorum {
provider: corosync_votequorum
expected_votes: 2
two_node: 1
wait_for_all: 1
}
nodelist {
node {
ring0_addr: snow01
nodeid: 1
}
node {
ring0_addr: snow02
nodeid: 2
}
}
You can download the following example file and adapt it to accommodate your needs.
Edit /etc/corosync/corosync.conf in snow01 and transfer this file to the other nodes:
scp -p /etc/corosync/corosync.conf snow02:/etc/corosync/corosync.conf
Start corosync service on all the nodes
systemctl start corosync
Xen configuration
Review if /etc/default/xendomains has an empty value for XENDOMAINS_SAVE variable or if it’s commented. Otherwise, comment this variable.
Test if Xen allows live migration between sNow! nodes
Execute the following commands in order to certify that the para-virtual machines can be migrated across the sNow! nodes:
From snow01 you can execute the following commands:
snow boot deploy01
xl migrate deploy01 snow02
If it works as expected, you should see an output message similar to the following example:
[4287] snow01:~ $ xl migrate deploy01 snow02
migration target: Ready to receive domain.
Saving to migration stream new xl format (info 0x0/0x0/799)
Loading new save file <incoming migration stream> (new xl fmt info 0x0/0x0/799)
Savefile contains xl domain config
xc: progress: Reloading memory pages: 26624/524288 5%
xc: progress: Reloading memory pages: 53248/524288 10%
xc: progress: Reloading memory pages: 78848/524288 15%
xc: progress: Reloading memory pages: 105472/524288 20%
xc: progress: Reloading memory pages: 131072/524288 25%
xc: progress: Reloading memory pages: 157696/524288 30%
xc: progress: Reloading memory pages: 184320/524288 35%
xc: progress: Reloading memory pages: 209920/524288 40%
xc: progress: Reloading memory pages: 236544/524288 45%
xc: progress: Reloading memory pages: 262144/524288 50%
xc: progress: Reloading memory pages: 288768/524288 55%
xc: progress: Reloading memory pages: 315392/524288 60%
xc: progress: Reloading memory pages: 340992/524288 65%
xc: progress: Reloading memory pages: 367616/524288 70%
xc: progress: Reloading memory pages: 393216/524288 75%
xc: progress: Reloading memory pages: 419840/524288 80%
xc: progress: Reloading memory pages: 446464/524288 85%
xc: progress: Reloading memory pages: 472064/524288 90%
xc: progress: Reloading memory pages: 498688/524288 95%
xc: progress: Reloading memory pages: 524482/524288 100%
migration target: Transfer complete, requesting permission to start domain.
migration sender: Target has acknowledged transfer.
migration sender: Giving target permission to start.
migration target: Got permission, starting domain.
migration target: Domain started successsfully.
migration sender: Target reports successful startup.
Migration successful.
Pacemaker
Setup the right permissions and check the cluster health
chown -R hacluster:haclient /var/lib/pacemaker
chmod 750 /var/lib/pacemaker
ssh snow02 chown -R hacluster:haclient /var/lib/pacemaker
ssh snow02 chmod 750 /var/lib/pacemaker
crm cluster health | more
Setup Pacemaker
The following steps can be automated taking advantage of the following script: setup_domains_ha.sh
#!/bin/bash
domain_list=$(snow list domains | egrep -v "Domain|------" | gawk '{print $1}')
crm_attribute --type op_defaults --attr-name timeout --attr-value 120s
rm -f pacemaker.cfg
echo "property stonith-enabled=no" > pacemaker.cfg
echo "property no-quorum-policy=ignore" >> pacemaker.cfg
echo "property default-resource-stickiness=100" >> pacemaker.cfg
echo "primitive xsnow-vip ocf:heartbeat:IPaddr2 params ip=\"10.1.0.254\" nic=\"xsnow0\" op monitor interval=\"10s\"" >> pacemaker.cfg
for domain in ${domain_list}; do
echo "primitive $domain ocf:heartbeat:Xen \\
params xmfile=\"/sNow/snow-tools/etc/domains/$domain.cfg\" \\
op monitor interval=\"40s\" \\
meta target-role=\"started\" allow-migrate=\"true\"
" >> pacemaker.cfg
done
echo commit >> pacemaker.cfg
echo bye >> pacemaker.cfg
crm configure < pacemaker.cfg
Otherwise, you can follow the next steps to setup Pacemaker:
Define global configuration
Iniciate the setup without STONITH. The last section explains how to setup STONITH using a fence device based on Xen.
[4242] snow01:~ $ crm configure
crm(live)configure# property stonith-enabled=no
crm(live)configure# property no-quorum-policy=ignore
crm(live)configure# property default-resource-stickiness=100
crm(live)configure# commit
crm(live)configure# bye
Define the first service in HA
Execute the crm configure and define the first service in HA as follows:
primitive deploy01 ocf:heartbeat:Xen \
params xmfile="/sNow/snow-tools/etc/domains/deploy01.cfg" \
op monitor interval="40s" \
meta target-role="started" allow-migrate="true"
Some operations like the live migration require some extra time. Especially when the VM uses a reasonable amount of memory. It’s highly recommended to increase the default timeout to avoid canceling the live migration due to a short time limit. The following example, setup 120s as default timeout. You can tune this value attending at your VM needs.
crm_attribute --type op_defaults --attr-name timeout --attr-value 120s
Test!
This is a good moment to test if the HA works. In order to review that, execute in a new SSH session the command:
crm_mon
It should report something like this:
Stack: corosync
Current DC: snow01 (version 1.1.16-94ff4df) - partition with quorum
Last updated: Fri Jul 28 06:51:02 2017
Last change: Fri Jul 28 06:50:50 2017 by root via crm_resource on snow02
2 nodes configured
1 resource configured
Online: [ snow01 snow02 ]
Active resources:
deploy01 (ocf::heartbeat:Xen): Started snow01
Using the following command, you will force to migrate the service from one node to the other one:
crm resource move deploy01 snow01
Define all the HA services
Follow the previous instructions to setup the services required to be in HA mode. The expected outcome should be something like this:
Stack: corosync
Current DC: snow01 (version 1.1.16-94ff4df) - partition with quorum
Last updated: Fri Jul 28 07:13:00 2017
Last change: Fri Jul 28 07:11:31 2017 by root via cibadmin on snow01
2 nodes configured
8 resources configured
Online: [ snow01 snow02 ]
Active resources:
deploy01 (ocf::heartbeat:Xen): Started snow01
proxy01 (ocf::heartbeat:Xen): Started snow01
monitor01 (ocf::heartbeat:Xen): Started snow02
nis01 (ocf::heartbeat:Xen): Started snow02
syslog01 (ocf::heartbeat:Xen): Started snow01
maui01 (ocf::heartbeat:Xen): Started snow02
nis02 (ocf::heartbeat:Xen): Started snow01
flexlm01 (ocf::heartbeat:Xen): Started snow02
Define floating IP for gateway
sNow! servers play a gateway role. The following instructions define HA for this service.
Execute the crm configure and define the xsnow-vip service as follows:
primitive xsnow-vip ocf:heartbeat:IPaddr2 params ip="10.1.0.254" nic="xsnow0" op monitor interval="10s"
commit
bye
Notice that this IP 10.1.0.254 must match with the IP defined in NET_SNOW and NET_COMP in the snow.conf
Service placement
In order to balance services across the two nodes and also to distribute additional services with native HA (i.e slurm-master slurm-slave) you can use the following instructions to define the preferred hosts. Failback is useful to define well-balanced services, but if you have an ongoing issue, you could trigger a failback in a “semi-faulty” node.
crm(live)# configure
crm(live)configure# location cli-prefer-maui01 maui01 role=Started inf: snow01
crm(live)configure# location cli-prefer-nis01 nis01 role=Started inf: snow01
crm(live)configure# location cli-prefer-proxy01 proxy01 role=Started inf: snow01
crm(live)configure# location cli-prefer-flexlm01 flexlm01 role=Started inf: snow02
crm(live)configure# location cli-prefer-monitor01 monitor01 role=Started inf: snow02
crm(live)configure# location cli-prefer-nis02 nis02 role=Started inf: snow02
crm(live)configure# location cli-prefer-syslog01 syslog01 role=Started inf: snow02
crm(live)configure# commit
crm(live)configure# bye